
O Q-learning evoluiu consideravelmente desde os primeiros experimentos comportamentais, como o condicionamento clássico de Pavlov, para se tornar uma das técnicas mais importantes no campo do Machine Learning. A seguir exploraremos como tem sido seu desenvolvimento e sua aplicação na neurorreabilitação e estimulação cognitiva.
Experimentos de Pavlov
Ivan Pavlov, um fisiologista russo do final do século XIX, é conhecido por estabelecer os fundamentos da psicologia comportamental através de suas experiências com o condicionamento clássico. Nestas experiências, Pavlov demonstrou que os cães podiam aprender a associar um estímulo neutro, como o toque de uma campainha, com um estímulo incondicionado, como a comida, provocando assim uma resposta incondicionada: a salivação.
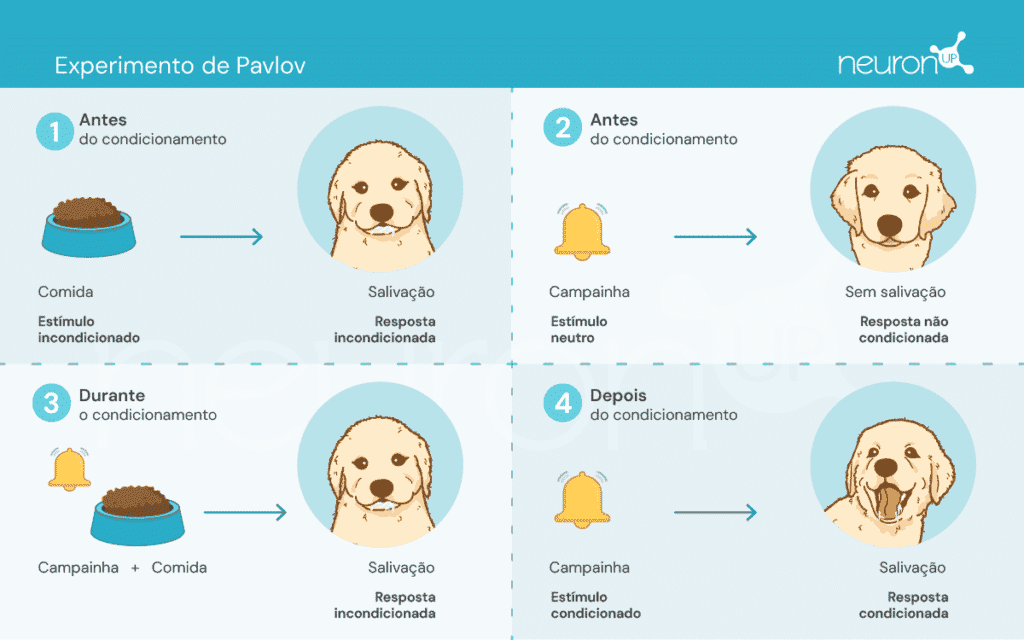
Este experimento foi fundamental para demonstrar que o comportamento pode ser adquirido por associação, um conceito crucial que mais tarde influenciou o desenvolvimento de teorias de aprendizagem por reforço.
As teorias de aprendizagem por reforço
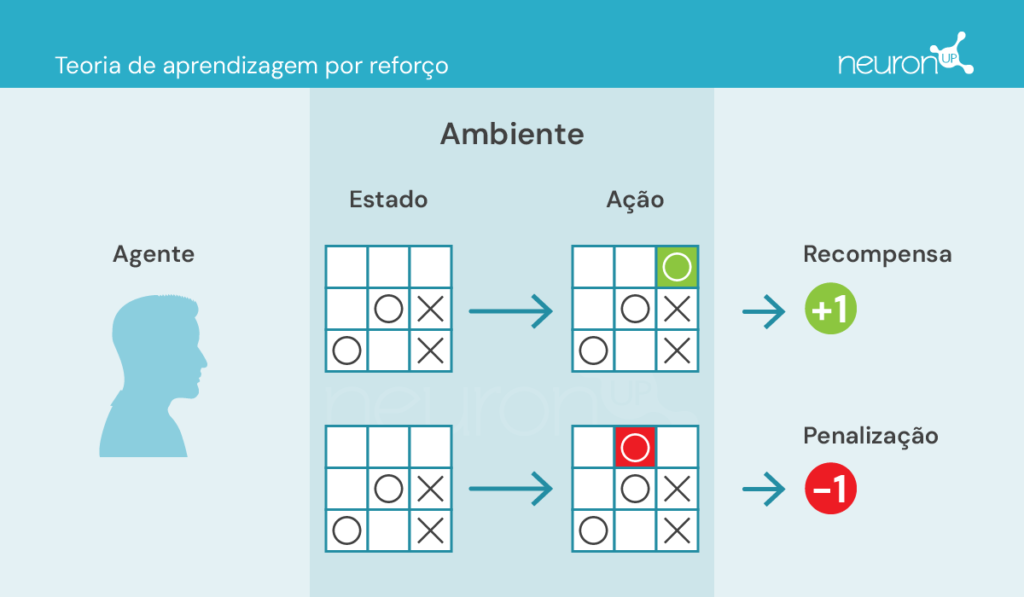
Essas teorias se concentram em como humanos e animais aprendem comportamentos a partir das consequências de suas ações, o que tem sido essencial para projetos de algoritmos como o Q-learning.
Existem alguns conceitos-chave com os quais precisamos nos familiarizar antes de continuar:
- Agente: responsável pela execução da ação.
- Ambiente: ambiente onde o agente se movimenta e interage.
- Estado: situação atual do ambiente.
- Ação: possíveis decisões tomadas pelo agente.
- Recompensa: recompensas dadas ao agente.
Nesse tipo de aprendizagem, um agente realiza ou executa ações no ambiente, recebe informações na forma de recompensa/penalidade e as utiliza para ajustar seu comportamento ao longo do tempo.
Um experimento clássico de aprendizagem por reforço é o experimento da caixa de Skinner, realizado pelo psicólogo americano Burrhus Frederic Skinner em 1938. Neste experimento, Skinner demonstrou que ratos poderiam aprender a pressionar uma alavanca para obter comida, usando o reforço positivo como meio de moldar o comportamento.
O experimento consiste em colocar um rato em uma caixa com uma alavanca que ele pode pressionar, um dispensador de comida e, às vezes, uma luz e um alto-falante.
Cada vez que o rato pressiona a alavanca, um grão de comida é liberado no dispensador. A comida atua como um reforço positivo, uma recompensa por pressionar a alavanca. Com o tempo, o rato começará a pressionar a alavanca com mais frequência, mostrando que aprendeu o comportamento por meio de reforço.
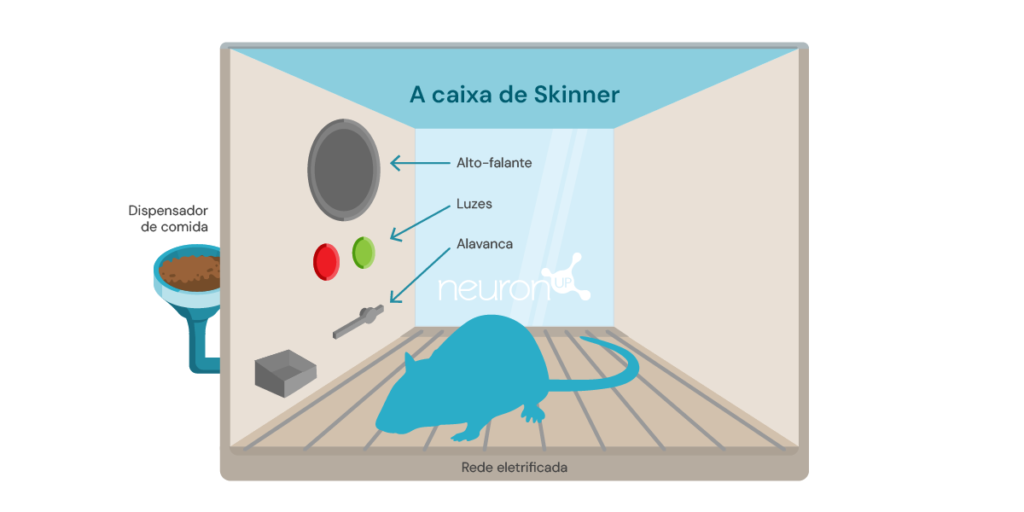
Esse tipo de aprendizado serviu de base para algoritmos de aprendizado de máquina, como o Q-learning, que permite que as máquinas aprendam comportamentos ideais de forma autônoma por meio de tentativa e erro.
O que é Q-learning?
O Q-learning foi introduzido por Christopher Watkins em 1989 como um algoritmo de aprendizagem por reforço. Este algoritmo permite que um agente aprenda o valor das ações num determinado estado, atualizando continuamente o seu conhecimento através da experiência, tal como o rato na caixa de Skinner.
Ao contrário dos experimentos de Pavlov, nos quais o aprendizado se baseava em associações simples, o Q-learning utiliza um método mais complexo de tentativa e erro. O agente explora diversas ações e atualiza uma tabela Q que armazena valores Q, que representam as recompensas futuras esperadas por realizar a melhor ação em um estado específico.
O Q-learning é aplicado em diversas áreas, como em sistemas de recomendação (como os utilizados pela Netflix ou Spotify), em veículos autónomos (como drones ou robôs) e na otimização de recursos. Exploraremos agora como esta tecnologia pode ser aplicada na neurorreabilitação.
Q-learning e NeuronUP
Uma das vantagens da NeuronUP é a possibilidade de customizar atividades de acordo com as necessidades específicas de cada usuário. No entanto, personalizar cada atividade pode ser entediante devido ao grande número de parâmetros a serem ajustados.
O Q-learning permite automatizar este processo, ajustando os parâmetros com base no desempenho do usuário nas diferentes atividades. Isto garante que os exercícios sejam desafiadores, mas alcançáveis, melhorando a eficácia e a motivação durante a reabilitação.
Como funciona?
Neste contexto, o agente, que poderia ser comparado a um usuário interagindo com uma atividade, aprende a tomar decisões ótimas em diferentes situações para superar corretamente a atividade.
O Q-learning permite que o agente experimente diversas ações interagindo com seu ambiente, recebendo recompensas ou penalidades e atualizando uma tabela Q que armazena esses valores Q. Esses valores representam as recompensas futuras esperadas por realizar a melhor ação em um determinado estado.
A regra de atualização do Q-learning é a seguinte:
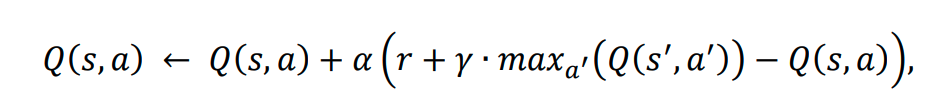
Onde:
𝛂 – é a taxa de aprendizagem.
r – é a recompensa recebida após a ação a do estado s.
𝛄 – é o fator de desconto, que representa a importância das recompensas futuras.
s’ – é o próximo estado.
– é o valor máximo de Q para os próximos estados s‘.
Exemplo de aplicação em uma atividade NeuronUP
Vejamos a atividade da NeuronUP chamada “Imagens Embaralhadas”, que trabalha habilidades como planejamento, práxis visual-construtiva e relacionamento espacial. Nesta atividade o objetivo é resolver um quebra-cabeça que foi misturado e cortado em pedaços.
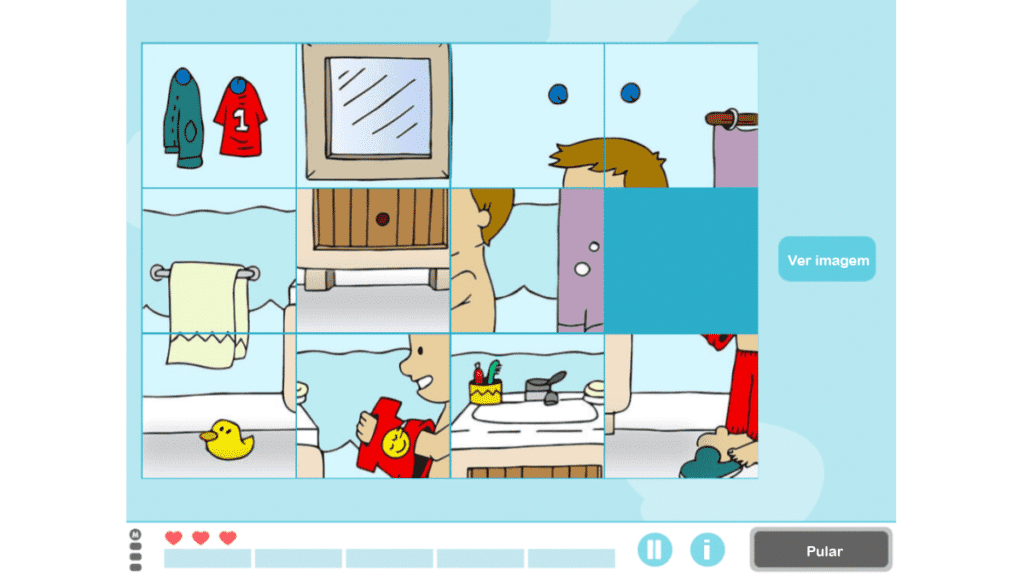
As variáveis que definem a dificuldade desta atividade são o tamanho da matriz (o número de linhas e colunas) bem como o valor da desordem das peças (baixa, média, alta ou muito alta).
Para entrenar al agente a resolver el rompecabezas, se creó una matriz de recompensas basada en el número mínimo de movimientos necesarios para resolverlo, definido por la siguiente fórmula:
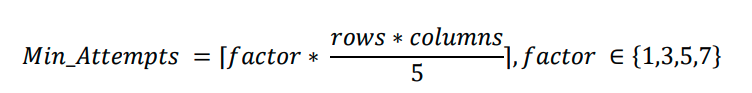
A variável do fator depende da variável do distúrbio. Uma vez criada a matriz, um algoritmo Q-learning foi aplicado para treinar o agente para resolver o quebra-cabeça automaticamente.
Essa integração inclui:
- Recuperação do valor Q: A função recupera o valor Q para um par estado-ação da tabela Q. Se o par estado-ação não tiver sido treinado antes, ela retorna 0. Esta função procura a recompensa esperada por realizar uma ação específica em um estado específico.
- Atualização do valor Q: A função atualiza o valor Q para um par estado-ação com base na recompensa recebida e no valor máximo Q do próximo estado. Esta função implementa a regra de atualização do Q-learning mencionada acima.
- Decisão sobre a acção a tomar: A função decide qual ação tomar em um determinado estado, usando uma estratégia epilson-greedy. Esta estratégia equilibra exploração e aproveitamento:
- Exploração: Consiste em selecionar a melhor ação conhecida até o momento. Com uma probabilidade ε (taxa de exploração, valor entre 0 e 1 que determina a probabilidade de explorar novas ações em vez de explorar ações conhecidas), uma ação aleatória é escolhida, permitindo ao agente descobrir ações potencialmente melhores.
- Aproveitamento: Consiste em testar outras ações além das mais conhecidas para descobrir se elas podem oferecer melhores recompensas no futuro. Com probabilidade 1−ε, o agente seleciona a ação com o maior valor de Q para o estado atual, utilizando seu conhecimento aprendido: a’ = argmaxaQ(s,a). Onde a’ é a ação que maximiza a função Q em um determinado estado s. Isso significa que, dado um estado s, selecione a ação a que possui o maior valor de Q.
Essas funções trabalham juntas para permitir que o algoritmo Q-learning desenvolva uma estratégia ideal para resolver o quebra-cabeça.
Análise preliminar da execução do algoritmo
O algoritmo foi aplicado a um quebra-cabeça matricial 2×3 com fator de dificuldade 1 (baixo), correspondendo a um número mínimo de tentativas igual a 2. O algoritmo foi executado no mesmo quebra-cabeça 20 vezes, aplicando as mesmas configurações de embaralhamento em cada vez e atualizando a tabela Q após cada etapa. Após 20 execuções, o quebra-cabeça foi embaralhado em uma configuração diferente e o processo foi repetido, resultando em um total de 2.000 iterações. Os valores iniciais dos parâmetros foram:
- Recompensa por resolver o quebra-cabeças: 100 pontos
- Pena por cada movimento: -1 ponto
A cada etapa, uma recompensa ou penalidade adicional era aplicada com base na quantidade correta de peças, permitindo ao agente entender seu progresso na resolução do quebra-cabeça. Isso foi calculado usando a fórmula:
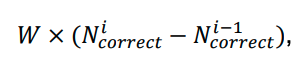
Onde:
- W é o fator de peso.
é o número de peças corretas após a jogada.
é o número de peças corretas antes da jogada.
O gráfico abaixo ilustra o número de movimentos necessários por iteração para o modelo resolver um quebra-cabeça de tamanho 2×3. Inicialmente, o modelo exige um grande número de movimentos, refletindo sua falta de conhecimento sobre como resolver o quebra-cabeça de forma eficiente. Porém, à medida que o algoritmo Q-learning é treinado, observa-se uma tendência de queda no número de movimentos, sugerindo que o modelo está aprendendo a otimizar seu processo de resolução.
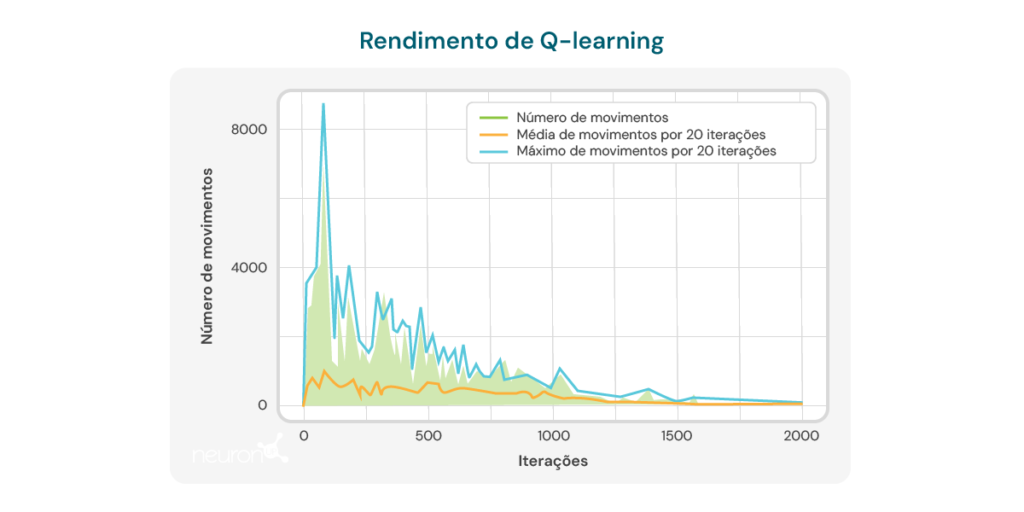

Esta tendência é uma indicação positiva do potencial do algoritmo para melhorar ao longo do tempo. No entanto, várias limitações importantes devem ser consideradas:
- Tamanho específico do quebra-cabeça: O algoritmo demonstra eficácia principalmente em quebra-cabeças com tamanho específico, como uma matriz 2×3. Ao alterar o tamanho ou a complexidade do quebra-cabeça, o desempenho do algoritmo pode diminuir significativamente.
- Tempo de cálculo: Quando o algoritmo é aplicado a configurações diferentes ou mais complexas, o tempo necessário para realizar os cálculos e resolver o quebra-cabeça aumenta consideravelmente. Isso limita sua aplicabilidade em situações que exigem respostas rápidas ou em quebra-cabeças de maior complexidade.
- Número de movimentos ainda elevado: Apesar da melhoria observada, o número de movimentos necessários para resolver o quebra-cabeça permanece relativamente alto, mesmo após múltiplas iterações. Nas últimas execuções, o modelo requer em média 8 a 10 movimentos, indicando que ainda há espaço para melhorar a eficiência do aprendizado.
Estas limitaciones subrayan la necesidad de un refinamiento adicional del algoritmo, ya sea ajustando los parámetros de aprendizaje, mejorando la estructura del modelo o incorporando técnicas complementarias que permitan un aprendizaje más eficiente y adaptable a diferentes configuraciones de puzzles. A pesar de estas limitaciones, no debemos olvidarnos de las ventajas que ofrece el Q-learning en la neurorrehabilitación, entre ellas:
- Personalização dinâmica de atividades: O Q-learning é capaz de ajustar automaticamente os parâmetros das atividades terapêuticas com base no desempenho individual do usuário. Isto significa que as atividades podem ser personalizadas em tempo real, garantindo que cada usuário trabalhe em um nível desafiador, mas alcançável. Isto é especialmente útil na neurorreabilitação, onde as capacidades dos utilizadores podem variar consideravelmente e mudar ao longo do tempo.
- Um aumento na motivação e comprometimento: Como as atividades são constantemente adaptadas ao nível de habilidade do usuário, evita-se a frustração com tarefas muito difíceis ou o tédio com tarefas muito simples. Isto pode aumentar significativamente a motivação e o compromisso do utilizador com o programa de reabilitação, o que é crucial para alcançar resultados bem sucedidos.
- Otimizando o processo de aprendizagem: Ao utilizar o Q-learning, o sistema pode aprender com as interações anteriores do usuário com as atividades, otimizando o processo de aprendizagem e reabilitação. Isso permite que os exercícios sejam mais eficazes, focando nas áreas onde o usuário necessita de mais atenção e reduzindo o tempo necessário para atingir os objetivos terapêuticos.
- Eficiência na tomada de decisão clínica: Os profissionais podem se beneficiar do Q-learning obtendo recomendações baseadas em dados sobre como ajustar as terapias. Isso facilita a tomada de decisões clínicas mais informadas e precisas, o que por sua vez melhora a qualidade dos cuidados prestados ao utente.
- Melhoria contínua: Com o tempo, o sistema baseado em Q-learning pode melhorar seu desempenho através do acúmulo de dados e da experiência do usuário. Isto significa que quanto mais o sistema é utilizado, mais eficaz se torna na personalização e otimização dos exercícios, oferecendo assim uma vantagem a longo prazo no processo de neurorreabilitação.
Concluindo, o Q-learning evoluiu desde suas raízes na psicologia comportamental e se tornou uma ferramenta poderosa em inteligência artificial e neurorreabilitação. A sua capacidade de adaptar atividades de forma autónoma torna-o um recurso valioso para melhorar a eficácia das terapias de reabilitação, embora ainda existam desafios a superar para otimizar plenamente a sua aplicação.
Bibliografía
- Bermejo Fernández, E. (2017). Aplicación de algoritmos de reinforcement learning a juegos.
- Giró Gràcia, X., & Sancho Gil, J. M. (2022). La Inteligencia Artificial en la educación: Big data, cajas negras y solucionismo tecnológico.
- Meyn, S. (2023). Stability of Q-learning through design and optimism. arXiv preprint arXiv:2307.02632.
- Morinigo, C., & Fenner, I. (2021). Teorías del aprendizaje. Minerva Magazine of Science, 9(2), 1-36.
- M.-V. Aponte, G. Levieux y S. Natkin. (2009). Measuring the level of difficulty in single player video games. Entertainment Computing.
- P. Jan L., H. Bruce D., P. Shashank, B. Corinne J., & M. Andrew P. (2019). The Effect of Adaptive Difficulty Adjustment on the Effectiveness of a Game to Develop Executive Function Skills for Learners of Different Ages. Cognitive Development, pp. 49, 56–67.
- R. Anna N., Z. Matei & G. Thomas L. Optimally Designing Games for Cognitive Science Research. Computer Science Division and Department of Psychology, University of California, Berkeley.
- Toledo Sánchez, M. (2024). Aplicaciones del aprendizaje por refuerzo en videojuegos.
Se você gostou deste artigo sobre Q-learning, provavelmente se interessará por estes artigos da NeuronUP:
O que vou encontrar na NeuronUP a partir de agora?
Vamos revisar as últimas novidades da NeuronUP. Faz apenas alguns dias que te informamos que, a partir de agora, você poderá se beneficiar de novas…

Limpe o cache e os cookies para aproveitar as atualizações
Informamos que lançamos uma nova versão de nossa plataforma com melhorias significativas e novos recursos. Para garantir que você possa aproveitar essas alterações, pedimos que…
Ler mais Limpe o cache e os cookies para aproveitar as atualizações

Reabilitação neuropsicológica no comprometimento cognitivo leve
Neste artigo, a psicóloga educacional Karina Alejandra García explica o que é deficiência cognitiva, como preveni-la e como tratá-la. Esse comprometimento da saúde cognitiva pode…
Ler mais Reabilitação neuropsicológica no comprometimento cognitivo leve

Estimulação magnética transcraniana e reabilitação cognitiva
María Alicia Lage, psicóloga habilitada para exercer atividades de saúde e neuropsicóloga clínica, Dr. Alejandro Fuertes-Saiz, psiquiatra, e Carla Castro, professora com especialização em educação…
Ler mais Estimulação magnética transcraniana e reabilitação cognitiva
Deixe um comentário